Consuming Tasks¶
To run the consumer, simply point it at the “import path” to your application’s
Huey instance. For example, here is how I run it on my blog:
huey_consumer.py blog.main.huey --logfile=../logs/huey.log
The concept of the “import path” has been the source of a few questions, but it is quite simple. It is simply the dotted-path you might use if you were to try and import the “huey” object in the interactive interpreter:
>>> from blog.main import huey
You may run into trouble though when “blog” is not on your python-path. To work around this:
Manually specify your pythonpath:
PYTHONPATH=/some/dir/:$PYTHONPATH huey_consumer.py blog.main.huey.Run
huey_consumer.pyfrom the directory your config module is in. I use supervisord to manage my huey process, so I set thedirectoryto the root of my site.Create a wrapper and hack
sys.path.
Warning
If you plan to use supervisord to manage your consumer process, be sure that you are running the consumer directly and without any intermediary shell scripts. Shell script wrappers interfere with supervisor’s ability to terminate and restart the consumer Python process. For discussion see GitHub issue 88.
Options for the consumer¶
The following table lists the options available for the consumer as well as their default values.
-l,--logfilePath to file used for logging. When a file is specified, by default Huey the logfile will grow indefinitely, so you may wish to configure a tool like
logrotate.Alternatively, you can attach your own handler to
huey.consumer.The default loglevel is
INFO.-v,--verboseVerbose logging (loglevel=DEBUG). If no logfile is specified and verbose is set, then the consumer will log to the console.
Note: due to conflicts, when using Django this option is renamed to use
-V,--huey-verbose.-q,--quietMinimal logging, only errors and their tracebacks will be logged.
-S,--simpleUse a simple log format consisting only of the time H:M:S and log message.
-w,--workersNumber of worker threads/processes/greenlets, the default is
1but most applications will want to increase this number for greater throughput. Even if you have a small workload, you will typically want to increase this number to at least 2 just in case one worker gets tied up on a slow task. If you have a CPU-intensive workload, you may want to increase the number of workers to the number of CPU cores (or 2x CPU cores). Lastly, if you are using thegreenletworker type, you can easily run tens or hundreds of workers as they are extremely lightweight.-k,--worker-typeChoose the worker type,
thread,processorgreenlet. The default isthread.Depending on your workload, one worker type may perform better than the others:
CPU heavy loads: use “process”. Python’s global interpreter lock prevents multiple threads from running simultaneously, so to leverage multiple CPU cores (and reduce thread contention) run each worker as a separate process.
IO heavy loads: use “greenlet”. For example, tasks that crawl websites or which spend a lot of time waiting to read/write to a socket, will get a huge boost from using the greenlet worker model. Because greenlets are so cheap in terms of memory, you can easily run a large number of workers. Note that all code that does not consist in waiting for a socket will be blocking and cannot be pre-empted. Understand the tradeoffs before jumping to use greenlets.
Anything else: use “thread”. You get the benefits of pre-emptive multi-tasking without the overhead of multiple processes. A safe choice and the default.
See the Worker types section for additional information.
-n,--no-periodicIndicate that this consumer process should not enqueue periodic tasks. If you do not plan on using the periodic task feature, feel free to use this option to save a few CPU cycles.
-d,--delayWhen using a “polling”-type queue backend, this is the number of seconds to wait when polling the backend. Default is 0.1 seconds. For example, when the consumer starts up it will begin polling every 0.1 seconds. If no tasks are found in the queue, it will multiply the current delay (0.1) by the backoff parameter. When a task is received, the polling interval will reset back to this value.
-m,--max-delayThe maximum amount of time to wait between polling, if using weighted backoff. Default is 10 seconds. If your huey consumer doesn’t see a lot of action, you can increase this number to reduce CPU usage.
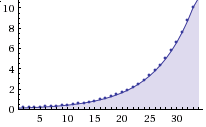
-b,--backoffThe amount to back-off when polling for results. Must be greater than one. Default is 1.15. This parameter controls the rate at which the interval increases after successive attempts return no tasks. Here is how the defaults, 0.1 initial and 1.15 backoff, look:
-c,--health-check-intervalThis parameter specifies how often huey should check on the status of the workers, restarting any that died for some reason. I personally run a dozen or so huey consumers at any given time and have never encountered an issue with the workers, but I suppose anything’s possible and better safe than sorry.
-C,--disable-health-checkThis option disables the worker health checks. Until version 1.3.0, huey had no concept of a “worker health check” because in my experience the workers simply always stayed up and responsive. But if you are using huey for critical tasks, you may want the insurance of having additional monitoring to make sure your workers stay up and running. At any rate, I feel comfortable saying that it’s perfectly fine to use this option and disable worker health checks.
-f,--flush-locksFlush all locks when starting the consumer. This may be useful if the consumer was killed abruptly while executing a locked task.
-L,--extra-locksAdditional lock-names to flush when starting the consumer, separated by comma. This is useful if you have locks within context-managers that may not be discovered during consumer startup, but you wish to ensure they are cleared. Implies
--flush-locks.-s,--scheduler-intervalThe frequency with which the scheduler should run. By default this will run every second, but you can increase the interval to as much as 60 seconds.
Examples¶
Running the consumer with 8 threads and a logfile for errors:
huey_consumer.py my.app.huey -l /var/log/app.huey.log -w 8 -q
Using multi-processing to run 4 worker processes.
huey_consumer.py my.app.huey -w 4 -k process
Running single-threaded with periodic task support disabled. Additionally, logging records are written to stdout.
huey_consumer.py my.app.huey -v -n
Using greenlets to run 50 workers, with no health checking and a scheduler granularity of 60 seconds.
huey_consumer.py my.app.huey -w 50 -k greenlet -C -s 60
Worker types¶
The consumer consists of a main process, a scheduler, and one or more workers. These individual components all run concurrently, and Huey supports three different mechanisms to achieve this concurrency.
thread, the default - uses OS threads. Due to Python’s global interpreter lock, only one thread can be running at a time, but this is actually less of a limitation than it might sound. The Python runtime can intelligently switch the running thread when an I/O occurs or when a thread is idle. If the worker is CPU-bound, the runtime will pre-emptively switch threads after a given number of operations, ensuring each thread gets a chance to make progress. Threads provide a good balance of performance and memory efficiency.
process - runs the scheduler and worker(s) in their own process. The main benefit over threads is the absence of the global interpreter lock, which allows CPU-bound workers to execute in parallel. Since each process maintains its own copy of the code in memory, it is likely that processes will require more memory than threads or greenlets. Processes are a good choice for tasks that perform CPU-intensive work.
greenlet - runs the scheduler and worker(s) in greenlets. Requires gevent, a cooperative multi-tasking library. When a task performs an operation that would be blocking (read or write on a socket), the file descriptor is added to an event loop managed by gevent, and the scheduler will switch tasks. Since gevent uses cooperative multi-tasking, a task that is CPU-bound will not yield control to the gevent scheduler, limiting concurrency. For this reason, gevent is a good choice for tasks that perform lots of socket I/O, but may give worse performance for tasks that are CPU-bound (e.g., parsing large files, manipulating images, generating reports, etc). Understand the tradeoff thoroughly before using this worker type.
When in doubt, the default setting (thread) is a safe choice.
Warning
Multiprocess support is not available for Windows. The only process start method available on Windows is “spawn”, which has the downside of requiring the Huey state to be pickled. Huey uses (and creates) many objects which cannot be pickled. More information here: multiprocessing documentation.
Using gevent¶
Gevent works by monkey-patching various Python modules, such as socket,
ssl, time, etc. In order for your application to be able to switch
tasks reliably, you should apply the monkey-patch at the very beginning of
your code – before anything else gets loaded.
Suppose we have defined an entrypoint for our application named
main.py, which imports our Huey instance, our tasks, and
the other essential parts of our application (the WSGI app, database
connection, etc).
We would place the monkey-patch at the top of main.py, before all the
other imports:
# main.py
from gevent import monkey; monkey.patch_all() # Apply monkey-patch.
from .app import wsgi_app # Import our WSGI app.
from .db import database # Database connection.
from .queue import huey # Huey instance for our app.
from .tasks import * # Import all tasks, so they are discoverable.
To run the consumer:
$ huey_consumer.py main.huey -k greenlet -w 16
You should have a good understanding of how gevent works, its strengths and limitations, before using the greenlet worker type.
Consumer shutdown¶
The huey consumer supports graceful shutdown via SIGINT. When the consumer
process receives SIGINT, workers are allowed to finish up whatever task
they are currently executing before the process exits.
Alternatively, you can shutdown the consumer using SIGTERM and any running
tasks will be interrupted, ensuring the process exits quickly.
Warning
Huey does not guarantee at-least-once delivery of messages, and does not do
acknowledgement of completed tasks. This means that if you terminate the
consumer without letting it finish any currently-executing tasks, those
tasks will be lost. To be alerted when this occurs, you can use Huey’s
Signals (specifically signals.SIGNAL_INTERRUPTED). The consumer
will emit this for tasks that are interrupted during execution.
Deployments¶
When deploying new code, your best bet is to gracefully shutdown the Huey
consumer using SIGINT, letting all running tasks finish, before starting a
new consumer process using the new code.
If you have long-running tasks, an alternative option is to configure
your new code to use a separate storage namespace. On Redis this is as simple
as specifying a new name for your RedisHuey() instance. Then you can
start the new code and new consumer, and they will operate independently of the
previously-running consumer. When all tasks are done, you can gracefully
shutdown the old consumer.
Note
It is always a good idea to implement a Huey signals.SIGNAL_INTERRUPTED
handler (Signals), even if all it does is log an exception about the
interrupted task.
Consumer restart¶
To cleanly restart the consumer, including all workers, send the SIGHUP
signal. When the consumer receives the hang-up signal, any tasks being executed
will be allowed to finish before the restart occurs.
Note
If you are using Python 2.7 and either the thread or greenlet worker model, it is strongly recommended that you use a process manager (such as systemd or supervisor) to handle running and restarting the consumer. The reason has to do with the potential of Python 2.7, when mixed with thread/greenlet workers, to leak file descriptors. For more information, check out issue 374 and PEP 446.
supervisord and systemd¶
Huey plays nicely with both supervisord, systemd and presumably any other process supervisor.
Barebones supervisor config using 4 worker threads:
[program:my_huey]
directory=/path/to/project/
command=/path/to/huey/bin/huey_consumer.py my_app.huey -w 4
user=someuser
autostart=true
autorestart=true
stdout_logfile=/var/log/huey.log
stderr_logfile=/var/log/huey.err
environment=PYTHONPATH="/path/to/project:$PYTHONPATH"
; Increase this if you want to ensure long-running tasks are not
; interrupted during shutdown.
stopwaitsecs=30
Barebones systemd config using 4 worker threads:
[Unit]
Description=My Huey
After=network.target
[Service]
User=someuser
Group=somegroup
WorkingDirectory=/path/to/project/
ExecStart=/path/to/huey/bin/huey_consumer.py my_app.huey -w 4
Restart=always
[Install]
WantedBy=multi-user.target
Note
Django users may replace huey/bin/huey_consumer.py with the appropriate
path to manage.py run_huey.
Multiple Consumers¶
Huey is typically run on a single server, with the number of workers scaled-up according to your applications workload. However, it is also possible to run multiple Huey consumers across multiple servers. When running multiple consumers, it is crucial that only one consumer be configured to enqueue periodic tasks.
By default the consumer will enqueue periodic tasks for execution whenever they
are ready to be run. When multiple consumers are used, it is therefore
necessary to specify the -n or --no-periodic option for all consumers
except one.
For example:
Server A (main):
huey_consumer.py myapp.huey -w 8 -k processServer B:
huey_consumer.py myapp.huey -w 8 -k process --no-periodicServer C:
huey_consumer.py myapp.huey -w 8 -k process --no-periodic
Since each Huey consumer must be able to communicate with the queue and result-store, Redis or another network-accessible storage backend must be used.
Consumer Internals¶
This section will attempt to explain what happens when you call a
task-decorated function in your application. To do this, we will go into
the implementation of the consumer. The code for the consumer
itself is actually quite short (couple hundred lines), and I encourage you to
check it out.
The consumer is composed of three components: a master process, the scheduler, and the worker(s). Depending on the worker type chosen, the scheduler and workers will be run in their threads, processes or greenlets.
These three components coordinate the receipt, scheduling, and execution of your tasks, respectively.
You call a function – huey has decorated it, which triggers a message being put into the queue (e.g a Redis list). At this point your application returns immediately, returning a
Resultobject.In the consumer process, the worker(s) will be listening for new messages and one of the workers will receive your message indicating which task to run, when to run it, and with what parameters.
The worker looks at the message and checks to see if it can be run (i.e., was this message “revoked”? Is it scheduled to actually run later?). If it is revoked, the message is thrown out. If it is scheduled to run later, it gets added to the schedule. Otherwise, it is executed.
The worker executes the task. If the task finishes, any results are stored in the result store. If the task fails, the consumer checks to see if the task can be retried. Then, if the task is to be retried, the consumer checks to see if the task is configured to wait a number of seconds between retries. Depending on the configuration, huey will either re-enqueue the task for execution, or tell the scheduler when to re-enqueue it based on the delay. If the consumer is killed abruptly or the machine powers off unexpectedly, any tasks that are currently being run by a worker will be “lost”.
While all the above is going on with the Worker(s), the Scheduler is looking at its schedule to see if any tasks are ready to be executed. If a task is ready to run, it is enqueued and will be processed by the next available worker.
If you are using the Periodic Task feature (cron), then every minute, the scheduler will check through the various periodic tasks to see if any should be run. If so, these tasks are enqueued.
Warning
SIGINT is used to perform a graceful shutdown.
When the consumer is shutdown using SIGTERM, any workers still involved in the execution of a task will be interrupted mid-task.
Signals¶
The consumer will emit certain Signals as it executes tasks. User code can register signal handlers to respond to these events. For more information, see the Signals document.